
Scrapy 爬虫开发
Installation
Scrapy 支持 Python2.7 及 3.4+,安装步骤按照官方文档进行
1 | # 安装 |
安装完毕后,目录结构如下所示
1 | crawler/ |
Scrapy 执行时的流程大致是
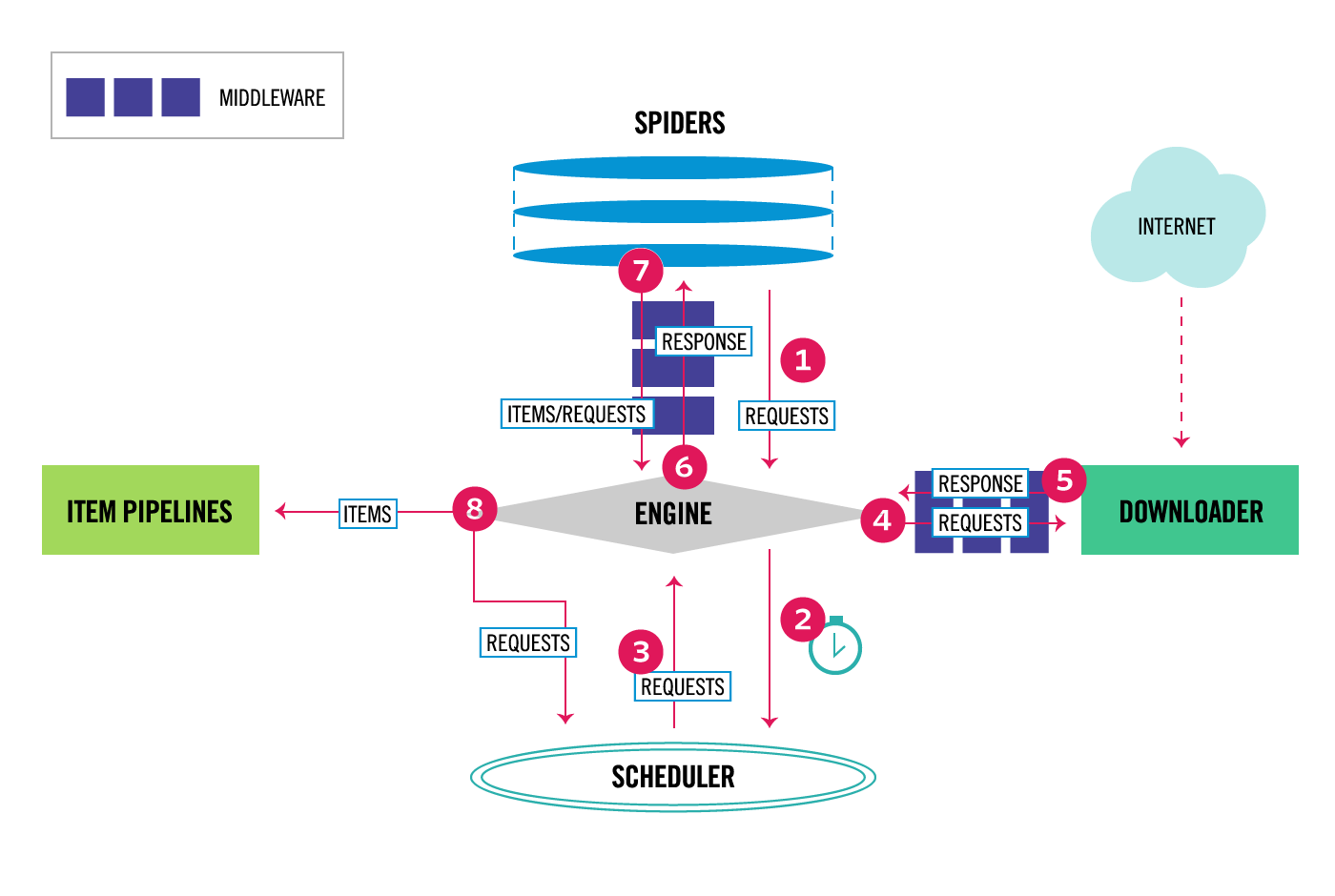
- Engine 从 Spider 获取
start_urls - Engine 将
start_urls发送到 Scheduler,并请求下一个爬取的 Request - Scheduler 将下一个要爬取 Request 返回给 Engine
- Engine 将收到的 Request 执行所有 Middleware 的
process_request()后,发送到 Downloader - Downloader 下载内容后,执行所有 Middleware 的
process_response()后,将结果返回给 Engine - Engine 将内容发送给 Spider 做数据处理,之前执行 Middleware 的
process_spider_input() - Spider 处理后,将结果通过 Middleware 的
process_spider_output()后,返回给 Engine - Engine 将处理后的数据发送给 Pipline 进行操作,并将处理过的 Request 发送给 Scheduler,请求下一个 Request
settings.py 配置文件中,一般需要修改的配置如下
1 | # 是否遵循 robots 协议 |
Spider
框架事先定义了几个通用的爬虫
scrapy.spiders.Spider最基本的爬虫scrapy.spiders.CrawlSpider最常用爬虫,能根据规则对全站网站进行爬取scrapy.spiders.XMLFeedSpiderscrapy.spiders.CSVFeedSpiderscrapy.spiders.SitemapSpider
CrawlSpider 继承了 Spider 外,提供了额外的属性和方法:
rules:是Rule对象的列表,定义了爬取网站的规则。它对不同的连接所需要执行的动作进行了定义。parse_start_url():start_url的请求返回时,该方法会被调用
Rule 对象主要作用为过滤有效链接,指定链接处理方法,并确定是否继续跟进
link_extractor从爬取的页面中提取指定格式的链接,生成新的 Request 请求,规则有allow,deny等,详细见官方文档callback对格式匹配的页面执行对应的处理方法cb_kwargs回掉函数的参数follow是否对页面中的连接继续跟进,当callback为None时默认为True,其他默认为Falseprocess_links过滤提取的链接process_request对指定链接 Request 请求进行处理
完整示例 crawlwer/spiders/ithome.py 如下所示
1 | import scrapy |
Items
用来定义结构化的结果
完整示例 crawler/items.py 如下所示
1 | import scrapy |
Middlewares
middleware 主要用来在下载,处理爬虫等前后,进行相关操作。
本次主要用来处理反爬虫。最基本反爬虫一般是通过浏览器的 UA,客户端的 IP,以及动态加载的 JS 来实现。于是针对以上措施,分别进行处理。
请求 UA 随机中间件
需要安装pip3 install fake-useragent,它从useragentstring.com和w3schools.com获取真实的浏览器 useragent,并在本地进行缓存
最早时从网上找了一些 UA,在本地做了一个随机获取,结果网上的 UA 已被翻爬虫过滤了,不能绕过反爬机制1
2
3
4
5
6
7
8
9from fake_useragent import UserAgent
class UserAgentMiddleware(object):
def __init__(self):
self.ua = UserAgent()
def process_request(self, request, spider):
request.headers.setdefault('User-Agent', self.ua.random)随机代理中间件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import redis
class ProxyMiddleware(object):
def __init__(self, from_url, proxy_pool_key):
self.redis = redis.from_url(from_url)
self.proxy_pool_key = proxy_pool_key
def from_crawler(cls, crawler):
return cls(
from_url=crawler.settings.get('REDIS_URL'),
proxy_pool_key=crawler.settings.get('PROXY_POOL_KEY'),
)
def process_request(self, request, spider):
proxy = self.redis.srandmember(self.proxy_pool_key)
if proxy:
proxy = proxy.decode()
spider.logger.info('Using proxy: %s', proxy)
request.meta['proxy'] = proxy
代理配置
服务器有多个IP,可以使用 squid 创建 http 代理服务器,通过设置代理不同端口使用不同的 IP 地址。
安装直接通过
apt-get install squid,安装完成后修改配置文件/etc/squid/squid.conf
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
acl port3128 localport 3128
acl port3129 localport 3129
acl port3130 localport 3130
acl port3131 localport 3131
acl port3132 localport 3132
acl port3133 localport 3133
# 定义访问控制,允许接入的地址
http_access allow all
# 定义监听的端口
http_port 3128
http_port 3129
http_port 3130
http_port 3131
http_port 3132
http_port 3133
# 定义转发地址
tcp_outgoing_address 172.16.0.106 port3128
tcp_outgoing_address 172.16.0.107 port3129
tcp_outgoing_address 172.16.0.108 port3130
tcp_outgoing_address 172.16.0.109 port3131
tcp_outgoing_address 172.16.0.110 port3132
tcp_outgoing_address 172.16.0.248 port3133
- CloudFlare 反爬虫,起主要反爬方法是通过 JS 生成本地 Cookie。
可以通过 scrapy_cloudflare_middleware 进行处理,直接安装pip3 install scrapy_cloudflare_middleware
启动的 Middlewares 需要写入 settings.py 配置文件
1 | # CloudFlare 反爬需要开启 cookie |
Piplines
1 | import pymongo |
在 settings.py 配置中增加
1 | ITEM_PIPELINES = { |
Distributed crawling
Scrapy Scheduler 和 Duplication Filter 本身使用了本地文件来来存储,不能进行水平的扩展。可以使用 Scrapy-Redis 来存放这些数据,使爬虫能够方便扩展,可以分布式部署。
安装通过 pip3 install Scrapy-Redis,安装后修改 settings 配置
1 | SCHEDULER = "scrapy_redis.scheduler.Scheduler" |
修改 Spider 继承 scrapy_redis.spiders.RedisCrawlSpider
1 | from scrapy_redis.spiders import RedisCrawlSpider |
由于任务是从 redis 中读取,所以 start_urls 需要直接存入 redis redis-cli lpush ithome:start_urls https://www.ithome.com
Deploy
只运行单个爬虫时,直接使用 scrapy crawl spider-name 命令来运行,按 Ctrl+C 来停止。
部署到服务器执行时,需要执行多个爬虫,可以通过 scrapyd 服务运行、监控。
首先安装 pip3 install scrapyd ,然后在项目目录创建配置文件 scrapyd.conf 如下
1 | [scrapyd] |
scrapyd 提供了 API 接口用来控制和监控爬虫
1 | # 列出可运行的所有爬虫 |
另外 scrapyd 还提供了一个 web 界面方便查看,由于 scrapyd 本身没有提供授权机制,可以使用 nginx 反向代理并设置 Basic Auth。创建 nginx 配置文件 /etc/nginx/sites-enabled/scrapyd
1 | server { |
生成密码文件
1 | htpasswd -c /etc/nginx/conf.d/.htpasswd username password |
Speed optimization
按照默认配置部署到服务器之后,发现服务器负载非常低,爬取速度也很慢。可以简单的修改配置加快爬虫速度
1 | CONCURRENT_REQUESTS = 100 |